技术
LLM
基础
大模型基础学习
阅读需 6 分钟
提醒
以下内容结合了公司培训课程和自己的理解,主要介绍了大模型是什么能做什么。
一. 大模型是什么?
大型语言模型(Large Language Model):是一种旨在理解和生成人类语言的人工智能模型。LLM通常包含数百亿(或更多)参数的语言模型,他们是在海量的文本数据上进行训练,从而获得对语言深层次的理解。国外的知名 LLM 有GPT-4,Gemini,Claude 和 LLaMA等,国内的有文心一言,讯飞星火,通义千问,ChatGLM,百川,混元,盘古等。 特点:
- 巨大的规模:LLM通常具有巨大的参数规模,可以达到数十亿甚至数千亿个参数。这使得它们能够捕捉更多的语言知识和复杂的语法结构。
- 预训练和微调:LLM采用了预训练和微调的学习方法。首先在大规模文本数据上进行预训练(无标签数据),学习通用的语言表示和知识。然后通过微调(有标签数据)适应特定任务,从而在各种 NLP 任务中表现出色。
- 上下文感知:LLM在处理文本时具有强大的上下文感知能力,能够理解和生成依赖于前文的文本内容。LLM在对话,文章生成和情境理解方面表现出色。
- 多语言支持:LLM可以用于多种语言,不仅限于英语。他们的多语言能力使得跨文化和跨语言的应用变得更加容易。
- 多模态支持:一些LLM已经扩展到支持多模态数据,包括文本,图像和声音。使得他们可以理解和生成不同媒体类型的内容,实现更多样化的应用。
- 高计算资源需求:LLM参数规模庞大,需要大量的计算资源进行训练和推理。通常需要使用高性能的GPU,TPU,NPU集群来实现。
总结
LLM产生语义理解,多语言处理,逻辑推理等能力。大模型列表
- 大模型就是一个函数,给输入,生成输出
- 任何可以用语言描述的问题,都可以输入文本给大模型,就能生成问题的结果文本
- 任意数据,都可以输入给大模型,生成任意数据,包括:文本,图像,音频,视频,数字等。
二.大模型能做什么?
以下是一些大模型对话产品
| 国家 | 公司 | 对话产品 | 旗舰大模型 | 网址 |
|---|---|---|---|---|
| 美国 | OpenAI | ChatGPT | GPT | https://chatgpt.com/ |
| 美国 | Gemini | Gemini | https://gemini.google.com/app | |
| 美国 | Anthropic | Claude | Claude | https://claude.ai/new |
| 美国 | xAI | Grok | Grok 3 | https://grok.com/ |
| 中国 | 阿里云 | 通义千问 | 通义千问 | https://www.tongyi.com/ |
| 中国 | 深度求索 | deepseek | DeepSeek | https://chat.deepseek.com/ |
| 中国 | 百度 | 文心一言 | 文心 | https://yiyan.baidu.com/ |
| 中国 | 智谱AI | 智谱清言 | GLM | https://chatglm.cn |
| 中国 | 月之暗面 | Kimi Chat | Moonshot | https://kimi.moonshot.cn/ |
| 中国 | MiniMax | 星野 | abab | https://www.minimaxi.com/ |
2.1 大模型能做的事情
- 文本生成:根据输入的文本提示,生成符合要求的文本内容,如文章、对话、代码等。
- 文本分类:将输入的文本分类为预定义的类别,如情感分析、主题分类等。
- 文本摘要:对输入的文本进行摘要,提取关键信息。
- 问答系统:回答用户的问题,提供相关信息。
- 翻译:将一种语言的文本翻译成另一种语言。
- 代码生成:根据输入的代码提示,生成符合要求的代码。
- 图像描述:根据输入的图像,生成对图像的描述文本。
- 语音识别:将语音转换为文本。
- 语音合成:将文本转换为语音。
- 情感分析:分析文本中的情感倾向,如正面、负面、中性等。
2.2 当前现状
应用场景上现象级产品少,主要在旧场景的增强和内部提效上。企业内部可以将大模型与业务相结合, 如营销场景下:ai营销创意+人工加工,ai批量生产营销素材,多语言翻译;办公场景下:公文撰写/总结/翻译。BI,情报分析;知识库场景下:ai知识库问答,ai知识库总结,ai知识库翻译等。
提示
如果你想找到适合自己业务的落地场景:
- 从最熟悉的领域入手
- 尽量找能用语言描述的任务
- 别求大而全,将任务拆解,先解决小任务,小场景
- 让AI学最厉害员工的能力,再让他辅助其他员工,实现降本增效
三. LLM应用
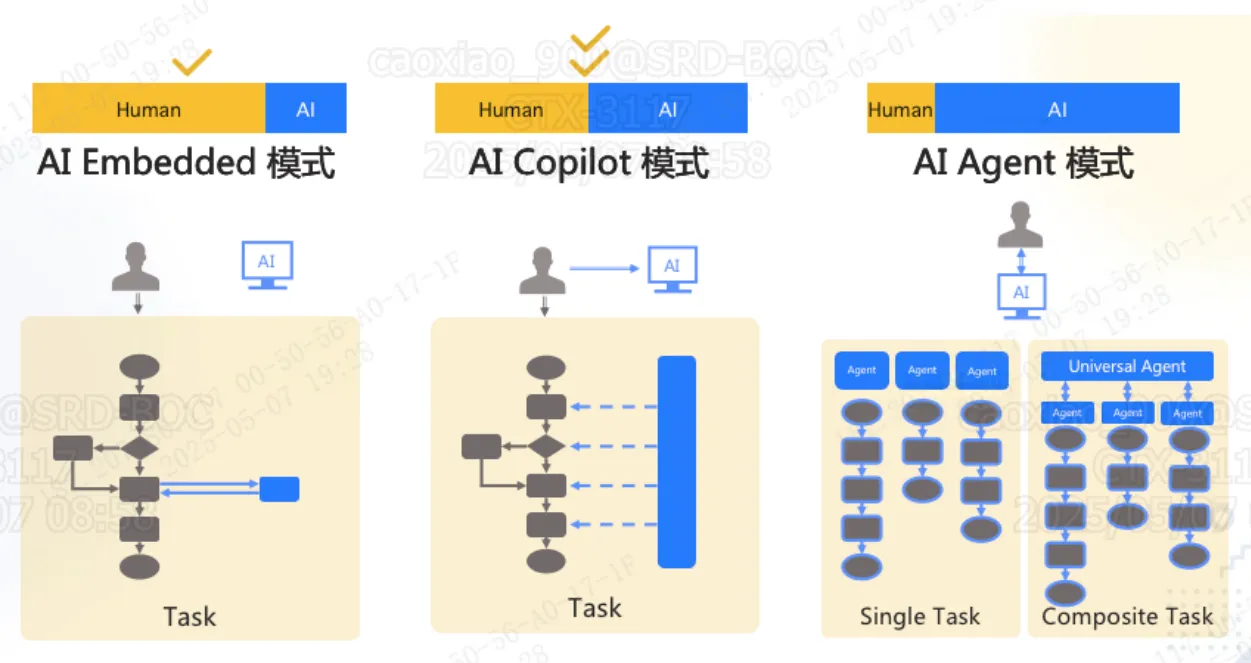 目前主流是多个 智能体(Agent)组成工作流
目前主流是多个 智能体(Agent)组成工作流
- 模仿人做事,将业务拆成工作流
- 每个智能体负责一个工作流节点
3.1 大模型的应用技术架构:
纯prompt
- prompt(提示词)是操作大模型的唯一输入,因此提示词工程也是大模型应用的关键。
- 纯prompt的方式,简单,但是功能有限,只能完成简单的任务。
Agent + Function Calling
- 智能体(Agent)负责协调和管理工作流,将不同的任务分配给不同的智能体。
- 函数调用(Function Calling)允许智能体调用外部函数,执行更复杂的任务,如调用API、数据库查询等。
- 场景:我输入我需要点外卖的提示词后,ai会通过函数调用外卖api,查询可用的外卖商家,然后返回商家列表。最后,我可以选择其中一个商家,ai会通过函数调用外卖api,下单。
RAG
- RAG(Retrieval-Augmented Generation)是指在生成式模型中,通过检索机制从外部知识库中获取相关信息,以增强模型的生成能力。
- Embedding模型:将文本转换为向量表示,用于检索。
- 向量数据库:存储和检索文本向量的数据库,用于支持RAG模型的检索功能。
- 向量搜索:根据输入的文本向量,在向量数据库中搜索最相似的文本向量,以获取相关信息。
- 举例:我输入“今天天气”,ai会将“今天天气”转换为向量表示,然后在向量数据库中搜索最相似的文本向量,如“今天天气是晴天”,最后返回“今天天气是晴天”。
Fine-tuning
- 微调(Fine-tuning)是指在预训练的大模型基础上,使用特定领域的数据集进行训练,以适应特定任务的需求。
- 场景:我有一个客户服务的数据集,我想训练一个大模型,能够根据客户的问题,自动回复客户。我可以使用微调技术,在预训练的大模型基础上,使用客户服务数据集进行训练,以适应客户服务的需求。
Loading Comments...